# 路径分隔符
- 在Windows 系统上为分号(;),在 UNIX 系统上为冒号(:)
# 文件名称分隔符
- 在 Windows 系统上为反斜线(\),在 UNIX 系统上为斜线(/)
- Java 程序中的反斜线表示转义字符,所以如果需要在 Windows 的路径下包括反斜线,则应该使用两条反斜线,如 F:\abc\test.txt
- Java 程序支持将斜线(/)当成平台无关的文件分隔符
# 行分隔符
- Windows 系统上为 \r\n,UNIX/Linux/BSD 等系统上为 \n
# 路径
- 绝对路径:在 Windows 等系统上,路径开头由盘符和一个 “:” 组成,在 UNIX 系统上,路径名开头是一条斜线(/)
- 相对路径:用户的工作路径,运行 Java 虚拟机时所在的路径(默认)
# 文本文件
- 当二进制文件里的内容能被正常解析成字符时,则该二进制文件就变成了文本文件
# Charset 类
- 编码(Encode)和解码(Decode)
- 标准字符集常量定义在 StandardCharsets 类中,如
UTF_8 - Java 默认使用 Unicode 字符集(Unicode 符号集只规定了符号的二进制代码)
- 常见的字符集:
ASCII:占一个字节,只能包含128个符号,不能表示汉字
ISO-8859-1(又称 latin-1):占一个字节,收录西欧语言,不能表示汉字
ANSI:占两个字节,在简体中文的操作系统中 ANSI 指的是 GB2312
GB2312、GBK、GB18030:占两个字节,支持中文
UTF-8:是一种针对 Unicode 的可变长度字符编码,又称万国码,是 Unicode 的实现方式之一 - 存储字母和数字:无论是什么字符集都占 1 个字节
存储汉字:GBK 家族占 2 个字节,UTF-8 占 3 个字节,UTF-16 占 2 个字节
String result = new String("汉字".getBytes("UTF-8"), "ISO-8859-1"); // 乱码
String message = new String(result.getBytes("ISO-8859-1"), "UTF-8");
// GBK 和 UTF-8 之间的乱码无法解决
2
3
# File 类
在 java.io 包下,只能操作文件和目录,不能访问文件内容本身
全局静态常量
- 路径分隔符(在 UNIX 系统上,该字符为
':', 在 Microsoft Windows 系统上,该字符为';'):char pathSeparatorChar、String pathSeparator - 文件名称分隔符(在 UNIX 系统上,该字符为
'/',在 Microsoft Windows 系统上,该字符为'\\'):char separatorChar、String separator
- 路径分隔符(在 UNIX 系统上,该字符为
构造器
File(String pathname):将给定的路径名字符串 pathname 转换为抽象路径名来创建 File 对象
File(String parent, String child):
File(File parent, String child):根据 parent 抽象路径名和 child 路径名字符串创建 File 对象
# 访问文件和目录
# 访问文件名
File file = new File("C:/abc/123.txt");String getName():返回此 File 对象所表示的文件名或目录名,123.txtString getPath():返回此 File 对象所对应的路径名,C:/abc/123.txtFile getAbsoluteFile():返回此 File 对象的绝对路径String getAbsolutePath():返回此 File 对象所对应的绝对路径名,C:/abc/123.txtFile getParentFile():返回此 File 对象所对应的父路径,如果没有,返回 null,C:/abcString getParent():返回此 File 对象所对应的父路径名
# 检测文件
boolean exists():判断 File 对象所对应的文件或目录是否真实存在boolean isFile():判断 File 对象所对应的是否是文件boolean isDirectory():判断 File 对象所对应的是否是目录boolean isAbsolute():判断 File 对象是否是绝对路径boolean canRead():判断 File 对象所对应的文件和目录是否可读boolean canWrite():判断 File 对象所对应的文件和目录是否可写boolean canExecute():判断应用程序是否可以执行此 File 对象所对应的文件或目录
# 获取常规文件信息
long length():获取文件内容的长度(单位为字节)(如果此路径名表示一个目录,则返回值是不确定的)long lastModified():获取文件的最后修改时间
# 操作文件
boolean createNewFile():当此 File 对象所对应的文件不存在但对应的父路径存在时,新建一个该 File 对象所指定的文件static File createTempFile(String prefix, String suffix):在默认的临时文件目录中创建一个临时的文件,使用给定前缀、 系统生成的随机数和给定后缀作为文件名(prefix 参数至少是 3 字节长,suffix 参数为 null 时,将使用默认的后缀“.tmp”)static File createTempFile(String prefix, String suffix, File directory):在 directory 所指定的目录中创建一个临时的文件,使用给定前缀、 系统生成的随机数和给定后缀作为文件名boolean mkdir():当此 File 对象所对应的目录不存在但对应的父目录存在时,新建一个 File 对象所对应的目录boolean mkdirs():新建一个 File 对象所对应的目录(包括所有必需但不存在的父目录)boolean delete():删除 File 对象所对应的文件或目录void deleteOnExit():注册一个删除钩子,指定当 Java 虚拟机退出时,删除 File 对象所对应的文件或目录boolean renameTo(File dest):用指定的路径名重新命名对 File 对象所对应的文件或路径File[] listFiles():列出 File 对象的所有子文件和子目录的绝对路径,返回 File 数组String[] list():列出 File 对象的所有子文件名和子目录的名称,返回 String 数组static File[] listRoots():列出系统所有的根路径
# 文件过滤器
String[] list(FilenameFilter filter)File[] listFiles(FilenameFilter filter):列出 File 对象的所有符合条件的子文件和目录,返回 File 数组- FilenameFilter 接口中的抽象方法:
boolean accept(File dir, String name) - 底层依次对指定 File 的所有子目录或者文件进行迭代,如果该方法返回 true,则 list() 方法会列出该子目录或者文件
// 列出 D:\JavaApps 目录下以“.java”结尾的文件(不包括子目录下)
File dir = new File("D:/JavaApps");
File[] fs = dir.listFiles(new FilenameFilter() {
// 底层传给 dir 的是 this, 传给 name 的是 this 中的子文件名或子目录名
public boolean accept(File dir, String name) {
return new File(dir, name).isFile() && name.endsWith(".java");
}
});
2
3
4
5
6
7
8
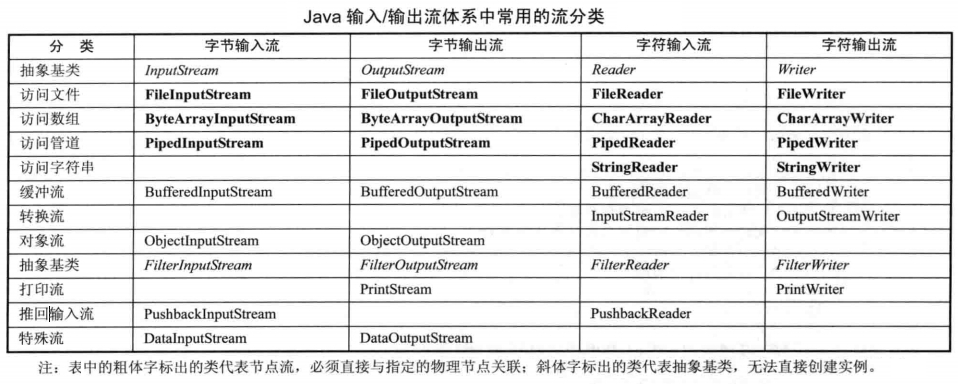
# IO 流概述
- 所有传统的流类型(类或抽象类)都放在 java. io 包下
- 流对象封装了用于保存输入或输出信息的缓冲空间,以及针对这个缓冲空间进行操作的方法
- 步骤:
- 创建节点对象
- 创建 IO 流对象
- 具体的 IO 操作(read()、write())
- 关闭 IO 流对象
- 输入流和输出流:从程序运行所在内存的角度来划分的
- 字节流和字符流
字节流操作的数据单元是 8 位的字节
字符流操作的数据单元是 16 位的字符(2个字节) - 节点流和处理流
- 节点流,和实际的输入/输出节点连接,流的构造器参数是一个物理节点
- 处理流(包装流),对已存在的节点流进行连接或封装,流的构造器参数是已经存在的流
- 使用处理流来包装节点流,程序通过处理流来执行输入/输出功能,让节点流与底层的 I/O 设备、 文件交互
- 4 个抽象基类:InputStream、OutputStream、Reader、Writer
- InputStreamReader、OutputStreamWriter 类是从字节流到字符流的桥梁
# 输入流:InputStream 和 Reader
- 创建字节/字符数组作为缓冲区,read in
int read():从输入流中读取一个字节/字符,返回所读取的字节数据/字符数据,如果已读到流的末尾,则返回 -1int read(byte[]/char[] buf):从输入流中最多读取 buf.Iength 个字节/字符的数据,并将其存储在字节数组/字符数组 buf 中,返回实际读取的字节数/字符总数,如果已读到流的末尾,则返回 -1int read(byte[]/char[] buf, int off, int len):从输入流中最多读取 len 个字节/字符的数据,并将其存储在字节数组/字符数组 buf 中,从数组的 off 位置开始放入,返回实际读取的字节数/字符总数,如果已读到流的末尾,则返回 -1
- 标准字节输入流,读取键盘的输入:System.in
# 输出流:OutputStream 和 Writer
write out
void write(int c):将指定的字节/字符 c 输出到输出流中void write(byte[]/char[] buf):将字节数组/字符数组 buf 中的数据输出到指定输出流中void write(byte[]/char[] buf,int off,int len):将字节数组/字符数组 buf 中从 off 位置开始,长度为 len 的字节/字符输出到输出流中void flush():刷新此输出流并强制写出所有缓冲的输出字节/字符(仅对缓冲输出流和字符输出流起作用)
Writer 类(字符输出流)中还包含如下两个方法
void write(String str):将 str 字符串里包含的字符输出到指定输出流中void write(String str, int off, int len):将 str 字符串里从 off 位置开始,长度为 len 的字符输出到指定输出流中
// 关闭资源的正确方式
// 方式 1
private static void test1() {
// 在 try...catch 外声明流对象
BufferedInputStream in = null;
BufferedOutputStream out = null;
try {
// 文件拷贝
in = new BufferedInputStream(new FileInputStream("src.txt"));
out = new BufferedOutputStream(new FileOutputStream("dest.txt", true));
byte[] buffer = new byte[8192];
int len = -1;
while ((len = in.read(buffer)) != -1) {
out.write(buffer, 0, len);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 在 finally 块中,每个流对象使用独立的 try...catch 关闭,并且在关闭前判断该流对象是否为 null
try {
if (in != null) {
in.close();
}
} catch (Exception e) {
e.printStackTrace();
}
try {
if (out != null) {
out.close();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
// 方式 2:Java 7 提供的自动资源关闭(推荐方式)
private static void test2() {
try ( // 创建实现了 AutoCloseable 接口的流对象
BufferedInputStream in = new BufferedInputStream(new FileInputStream("src.txt"));
BufferedOutputStream out = new BufferedOutputStream(new FileOutputStream("dest.txt", true));
// ByteArrayOutputStream out = new ByteArrayOutputStream();
) {
byte[] buffer = new byte[8192];
int len = -1;
while ((len = in.read(buffer)) != -1) {
out.write(buffer, 0, len);
}
// byte[] bytes = out.toByteArray();
} catch (Exception e) {
e.printStackTrace();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
# 节点流
# 文件流
- 访问文件
# FilelnputStream 和 FileReader
构造器(当指定 File 对象对应的文件不存在时,会在对应的目录下新建该文件)
FileInputStream(File file)、FileInputStream(String name)
FileReader(File file)、FileReader(String fileName)FileReader 是以当前机器的默认字符集来读取文件的(
Charset.defaultCharset().name()),如果需要指定字符集,应使用 InputStreamReader 和 FileInputStream;JDK 11+ FileReader 新增了带 Charset 参数的构造器:FileReader(File file, Charset charset)
# FileOutputStream 和 FileWriter
构造器(当指定 File 对象对应的文件不存在时,会在对应的目录下新建该文件)
FileOutputStream(File file, boolean append)、FileOutputStream(String name, boolean append)
FileWriter(File file, boolean append)、FileWriter(String fileName, boolean append)FileWriter 是以当前机器的默认字符集来写文件的
Charset.defaultCharset().name()
# 数组流(内存流)
访问数组:字节流以字节数组为节点,字符流以字符数组为节点
ByteArrayInputStream、ByteArrayOutputStream
CharArrayReader、CharArrayWriter访问字符串
StringReader、StringWriterByteArrayInputStream / ByteArrayOutputStream 等都是对内存中的字节数据的访问,是一个虚拟的流,没有占用网络、磁盘文件等资源,所以没有关闭的必要,实现上也是空,但是对流进行关闭是一个好习惯
# 管道流(线程通讯流)
- 将 A 线程的管道输出流连和 B 线程的管道输入流连接(connect)来实现线程之间通信功能
- PipedlnputStream、 PipedOutputStream
PipedReader、 PipedWriter
# Scanner 类进行输入操作
java.util 包中,可以使用正则表达式来解析基本类型和字符串的简单文本扫描器
构造器
Scanner(File source, String charsetName)
Scanner(InputStream source, String charsetName)
Scanner(String source):创建一个从指定字符串扫描的扫描器实例方法:(xxx表示数据类型,如byte、int 、boolean等)
boolean hasNextXxx():判断此扫描器输入信息中的下一个标记是否可以解释为一个 xxx 值
Xxx nextXxx():将输入信息的下一个标记扫描为一个 xxx 值
boolean hasNextLine():如果在此扫描器的输入中存在另一行,则返回 true
String nextLine():此扫描器执行当前行,并返回跳过的输入信息
Scanner useDelimiter(Pattern pattern):将此扫描器的分隔模式设置为指定模式,返回 this
# Properties 类加载配置文件
void load(InputStream inStream)
void store(OutputStream out, String comments)
# 访问其它进程
以子进程为节点:用于本进程读写其他进程中的数据
Process 类中用于让程序和其子进程进行通信的实例方法:
InputStream getInputStream():获取子进程的输入流
OutputStream getOutputStream():获取子进程的输出流
InputStream getErrorStream():获取子进程的错误流
# RandomAccessFile
可以自由访问文件的任意地方
构造器
RandomAccessFile(File file, String mode)
RandomAccessFile(String name, String mode)
模式参数:"r"、"rw"、"rws" 或 "rwd"实例方法
void writeXxx(xxx v):按 x 个字节将 v 入该文件
void readXxx(xxx v):从此文件读取一个 xxx(注意:writeXxx 和 readXxx 必须要对应起来,writeByte 写出的数据,此时只能使用 readByte 读取回来)
void writeUTF(String str):使用 modified UTF-8 编码将一个字符串写入该文件(比 UTF-8 多 2 个字节)
String readUTF():从此文件读取一个字符串
long getFilePointer():返回此文件中的当前偏移量
void seek(long pos):设置到此文件开头测量到的文件指针偏移量,在该位置发生下一个读取或写入操作
int skipBytes(int n):尝试跳过输入的 n 个字节以丢弃跳过的字节
long length():返回此文件的长度
void setLength(long newLength):设置此文件的长度
# 处理流
- 关闭输入/输出流资源时,只要关闭最上层的处理流即可
# 缓冲流
- 默认缓冲区大小为 8192 个字节或字符
# BufferedInputStream 和 BufferedReader
构造器
BufferedInputStream(InputStream in)、BufferedReader(Reader in)BufferedReader 类(字符缓冲输入流)中特有的方法
String readLine():读取一个文本行(换行 '\n' 或回车 '\r'),如果已到达流末尾,则返回 null
# BufferedOutputStream 和 BufferedWriter
构造器
BufferedOutputStream(OutputStream out)、BufferedWriter(Writer out)BufferedWriter 类(字符缓冲输出流)中特有的方法
void newLine():写入一个行分隔符(由系统属性 line.separator 定义)
# 转换流
将字节流转换成字符流:InputStreamReader、OutputStreamWriter
构造器
InputStreamReader(InputStream in, String charsetName)
OutputStreamWriter(OutputStream out, String charsetName)转换流特有的方法
String getEncoding():返回此流使用的字符编码的名称
# 顺序流(合并流)
- 把多个字节输入流合并成一个字节输入流对象
- SequenceInputStream
构造器:SequenceInputStream(InputStream s1, InputStream s2)
# 对象流
ObjectInputStream
构造器:ObjectInputStream(InputStream in)
实例方法:Object readObject():从 ObjectInputStream 读取对象(可能需要强转)ObjectOutputStream
构造器:ObjectOutputStream(OutputStream out)
实例方法:void writeObject(Object obj):将指定的对象写入 ObjectOutputStream对象序列化机制允许将内存中实现序列化的 Java 对象转换成字节序列(二进制流),使得对象可以脱离程序的运行而独立存在(保存到磁盘上或者通过网络传输)
对象的序列化(Serialize) :将一个 Java 对象写入二进制流中
对象的反序列化(Deserialize) :从二进制流中恢复该 Java 对象(反序列化时必须存在对象的字节码对象)
支持序列化机制的对象的类必须实现 Serializable 接口(标识接口,无抽象方法)
序列化时,会跳过 transient 或 static 关键字修饰的字段
为了在反序列化时确保序列化版本的兼容性,最好在每个要序列化的类中定义一个 private static final long serialVersionUID 字段,用于标识该 Java 类的序列化版本号(具体数值可以自己定义),如果不显式定义 serialVersionUID 类变量的值,该类变量的值将由 JVM 根据类的相关信息计算
# 打印流
都是输出流
PrintStream 构造器
PrintStream(File file, String csn)
PrintStream(String fileName, String csn)
PrintStream(OutputStream out)PrintWriter 构造器
PrintWriter(File file, String csn)
PrintWriter(String fileName, String csn)
PrintWriter(Writer out, boolean autoFlush)
如果 autoFlush 为 true,则在调用 println、printf 或 format 的其中一个方法时将刷新输出缓冲区,否则只会在调用 flush、close 方法时才会写出所有缓冲的输出字符实例方法
void print(Object o):打印任意类型数据值或对象的字符串值
void println(Object o):打印任意类型数据或对象的字符串值,然后换行
PrintStream printf(String format, Object... args):使用指定格式字符串和参数将格式化的字符串写入此输出流标准字节打印流,输出到显示器:System.out
标准错误字节打印流:System.errSystem 类中重定向标准输入/输出的类方法
void setIn(InputStream in):将 System.in 的输入重定向到其它输入流
void setOut(PrintStream out):将 System.out 的输出重定向到其它打印流
void setErr(PrintStream err):将 System.err 的输出重定向到其它打印流
# 数据流
- DataInputStream:从二进制流中读取字节,并根据所有基本类型数据进行重构
- DataOutputStream:将数据从任意基本类型转换为一系列字节,并将这些字节写入二进制流
- 注意:writeXxx 和 readXxx 必须要对应起来,writeByte 写出的数据,此时只能使用 readByte 读取回来
# Java 4 的 NIO
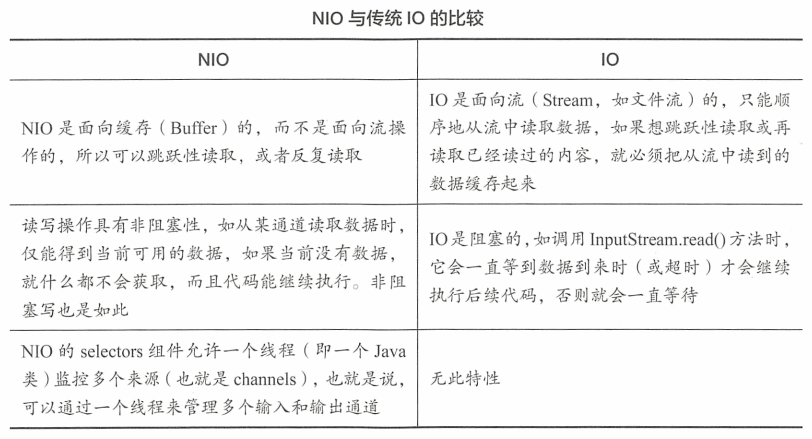
- NIO 的三大重要组件:Channel(通道)、Buffer(缓冲区)和 Selector(选择器)
- 通道(Channel)与传统 IO 中的流(Stream)类似,表示打开到 IO 设备(例如:文件、套接字)的连接,但通道是双向的,而 Stream 是单向的,输入流只负责输入,输出流只负责输出
- 在 NIO 中,有 FileChannel、SocketChannel、ServerSocketChannel 和 DatagramChannel 4 种 Channel 对象,第一种是针对文件的,后三种是针对网络编程的
- 唯一能与通道交互的组件是缓冲区(Buffer),通过通道,可以从缓冲区中读写数据
- Buffer 对象用来缓存读写的内容,在 NIO 中,通过 Channel 对象来进行读写操作,通过 Buffer 对象缓存读写的内容
- 选择器(Selector)可以同时监控多个 SelectableChannel 的 IO 状况,是非阻塞 IO 的核心
- FileChannel 不能与 Selector —起使用,因为 FileChannel 不能切换到非阻塞模式
// 文件拷贝
int bufferSize = 1024; // 定义缓存区的长度
// 定义了两个 FileChannel 对象,用来指向待读写的文件
FileChannel src = new FileInputStream("D:\\src.txt").getChannel();
FileChannel dest = new FileOutputStream("D:\\dest.txt").getChannel();
// 通过 allocate() 方法来给 ByteBuffer 分配空间
ByteBuffer buffer = ByteBuffer.allocate(bufferSize);
// 通过 while 循环从 src 里逐行读
while (src.read(buffer) != -1) {
buffer.flip(); // 切换读写模式
dest.write(buffer); // 向 dest 里写
buffer.clear(); // 清空缓存,以便下次读
}
// 内存映射文件缓冲器:采用内存映射文件的方式来处理输入/输出,将文件或文件的一段区域映射到内存中
int length = 1024 * 1024 * 10; //10M
MappedByteBuffer buffer = new RandomAccessFile("D:\\bigFile.text", "rw").getChannel().map(FileChannel.MapMode.READ_WRITE, 0, length);
// 写文件
for (int i = 0; i < length; i++) {
buffer.put((byte) 'a');
}
// 只读其中的前 10 位
for (int i = 0; i < 10; i++) {
System.out.print((char) buffer.get(i));
}
// 使用 FileChannel 的 transferTo 方法进行流的复制
FileChannel in = FileChannel.open(Paths.get("src.txt"), StandardOpenOption.READ);
FileChannel out = FileChannel.open(Paths.get("dest.txt"), CREATE, WRITE);
in.transferTo(0, in.size(), out);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# Java 7 的 NIO.2(AIO)
# Path 接口、Files 和 Paths 工具类
- Paths 中的类方法
Path get(String first, String... more) - Files 中的用于文件拷贝的类方法
Path copy(Path source, Path target, CopyOption... options)
long copy(InputStream in, Path target, CopyOption... options)
long copy(Path source, OutputStream out) - Files 中其它的类方法:isHidden、exists、createFile、move、deleteIfExists、newBufferedReader、newBufferedWriter、readAllLines、lines、size、write、list、walk、find、probeContentType
// 根据文件扩展名获取 MIME Type
Files.probeContentType(new File(filePath).toPath());
URLConnection.getFileNameMap().getContentTypeFor(filePath); // 识别类型不及上一方法多
new MimetypesFileTypeMap().getContentType(new File(filePath)); // 大部分返回 application/octet-stream
Files.write(Paths.get("hello.txt"), "你好 hi".getBytes(StandardCharsets.UTF_8), StandardOpenOption.CREATE, StandardOpenOption.TRUNCATE_EXISTING);
// 注意读取超出内存大小的大文件时会出现 OOM
List<String> allLines = Files.readAllLines(Paths.get("hello.txt"), StandardCharsets.UTF_8);
// 使用使用流式处理时,注意释放资源,避免产生 too many open files
try (Stream<String> lines = Files.lines(Paths.get("hello.txt")).skip(10000).limit(10000)) {
lines.forEach(System.out::println);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 使用 FileVisitor 遍历文件和目录
Files 类遍历文件的类方法
Path walkFileTree(Path start, FileVisitor<? super Path> visitor):遍历 start 路径下的所有文件和子目录
Path walkFileTree(Path start, Set<FileVisitOption> options, int maxDepth, FileVisitor<? super Path> visitor):与上一个方法的功能类似,该方法最多遍历 maxDepth 深度的文件通过继承 SimpleFileVisitor(FileVisitor的实现类)来实现自己的 “ 文件访问器”